
A Detailed Guide to Data-Driven
Testing
Data-driven or parameterized testing is a way to automate the creation, use, and management of (virtually unlimited) pools of test input data. This guide covers everything you need to know to implement data-driven testing in your existing or brand-new test automation practices.

What is Data-Driven Testing?
Imagine a scenario where you have to automate a test for an application with multiple input fields. Typically, or for one-off scenarios, you would hardcode those inputs and execute the test. But hardcoding will fail at scale. Hardcoding inputs will quickly become cumbersome, confusing, and impossible to manage when you have to run through many permutations of acceptable input values for best-case, worst-case, positive, and negative test scenarios.
If you could have all test input data stored or documented in a single spreadsheet, you can program the test to “read” the input values from it. That is precisely what data-driven testing tries to achieve.
DDT separates test logic (script) from test data (input values), making both easier to create, edit, use, and manage at scale. Therefore, DDT is a methodology where a sequence of test steps (structured in test scripts as reusable test logic) are automated to run repeatedly for different permutations of data (picked up from data sources) to compare actual and expected results for validations.
So, parametrized testing is a four-step process that involves:
Fetching input data from the data sources like .xls, .csv, .xml files or other databases.
Entering input data into the AUT (application under test) using automated test scripts and variables.
Comparing the actual results with the expected output.
Running the same test again with the next row of data (from the same source).
Automating Data-Driven Testing Using Selenium: Common Scenarios
Let's explore some scenarios to understand how DDT can be conceptualized and implemented using Selenium.
Scenario 1: Login panel
A login panel in an application asks the user to provide a work email and a password. Allowing only a registered user is critical here: the login feature is built to block unauthorized users from accessing certain features/data in the application.
To authenticate the email and password, you will need to check if both input field types match the data entered at the time of successful sign-up.
To check these individual cases, you will have to input different variables every time a script is run to test the authentication/login process. To parametrize this test, you can save different variables in a storage file and call these values individually in a functional test script.
A DDT test script for this login authentication scenario built with Selenium could look something like this:
pip install selenium from selenium import webdriver driver = webdriver.Chrome() def site_login(): driver.get (“URL”) driver.find_element_by_id(“ID”).send_keys(“username”) driver.find_element_by_id (“ID”).send_keys(“password”) driver.find_element_by_id(“submit”).click() #if you are using FB then, def fb_login(): driver.find_element_by_id(“email”).send_keys(‘fakeemail@crossbrowsertesting.com’) driver.find_element_by_id(“pass”).send_keys(“fakepassword1”) driver.find_element_by_id(“loginbutton”).click() from Selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait WebDriverWait(driver, until(EC.title_contains(“home”))A test file could look something like this:

Scenario 2: (Exhaustively) Testing file format for the 'File Upload' feature
For a file upload feature, it is imperative that the format/template of the file that the user uploads is acceptable, but there is more to it than just matching formats. The data in the file is also expected to be picked up by the application that processes it for a specific use case (like generating a graph). Let's say the application uses a .csv file to store data, then the test should ideally help validate the data type in every cell of the .csv file. Here, testing the content type in every cell according to a certain type takes precedence.
Therefore, the test should be focused on checking the format of supported and unsupported files, failing when the file format doesn't meet acceptable criteria. Supported files should be enabled and uploaded without any data loss. For instance, if the upload file should have just two columns with a specific header, it should not accept files that don't meet this criterion.
Let's say the requirement suggests we upload a file with two columns with a single header each. The rest of the content in the file should not have any special characters between the cell contents. Should the file format be correct, the application is triggered to read the right data in every cell to be processed further. This test has to run for all cells across all rows and columns. This is where DDT can help.
A sample template could look something like this:
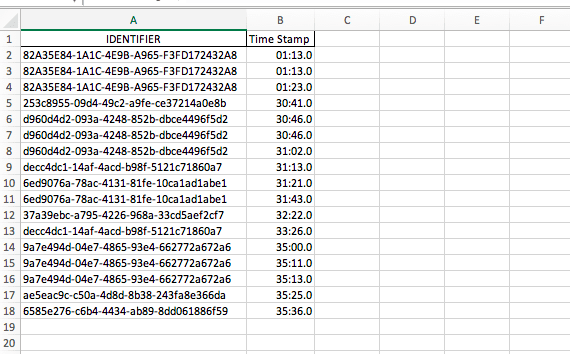
All of the aforementioned scenarios can be automated using a DDT-compatible automation framework. This enables teams to create test scripts with placeholders that get replaced with input values from the test data file, which are then compared with the expected results.
Implementing Data-Driven Test Automation
In a generic automated test, you include sample data in the test script itself. But in data-driven testing, you must connect your test to an external data source, which can be excel files, .csv and .xml files, or even fully-featured databases like MySQL.
There are three steps by which you can automate data-driven testing:
Choosing the data source.
Connecting the data source.
Assessing the results.
If you have no test automation, you can start off easy with DDT. But to implement DDT in your current automation testing framework, you will need to:
Re-create test scripts to use variables and conditional logic (in order to use test data from an external file/database)
Compare results with expected output data, also stored in a file.
Thus, the single most important thing is knowing how to structure your test data. Take a look at the flow diagram below. This replicates a typical data-driven testing framework.

Data File and Test Data
A data file is the first point of input for any type of DDT framework. You can have multiple files for a range of scenarios that test:
- positive and negative test cases,
- exception throwing and exception handling test cases,
- min-max limit cases, and
- all the permutations of input data that amount to appropriate data coverage for your application.
This data file is only usable if you can parse this data through the Driver Script based on the test logic. These data sets can be stored in data storage files such as excel, .xml, .json, .yml, or even an HDP database.
Pro-tip: Include hash (key, value pairs), arrays, and data tables to structure big data coherently for data-driven testing.
Driver Script
Note: If you are using a codeless automation platform that has built-in features for DDT, like Testsigma, you don't need to manage this.
Driver script 'carries out' the actions specified in the test script. It works like an executable file. The driver script reads data from the data files used in the test scripts to execute corresponding tests on the application and then outputs results. It may also compare the output with 'expected results' if specified.
A driver script is often a simple piece of code written efficiently. A driver script in DDT usually contains the application code and the implementation code that works together. Overall, DDT revolves around how efficiently an application can be tested. Technically, it's about how the test data works with the test script to bring out expected results.
Data-Driven scripts are similar to application-specific scripts (pyspark script, JavaScript) programmed to accommodate variable datasets.
Automation scripts with dynamic variables. In DDT, everything is tested dynamically with different variables of data sets. Therefore, you need modified scripts capable of handling dynamic data and its behavior when the application runs.
Duplication of the test design. This is often tricky but doable! The idea is to have the workflow followed in manual testing duplicated or reproduced in the automation workflow. This will allow the same test design that a manual tester would follow to be automated by an automation process. Comparing the two, manual testing cushions the way an application works by manually triggering the next process in real-time, whereas automation workflow tests this transition through code which should work seamlessly without any intervention.
This brings us to the last part of this section.
Expected vs. Actual Results
Within a DDT framework, you understand how your application works with user data. So when your application gives an output, the output needs validation. This validation is achieved by comparing the actual output against the expected ones. If there are mismatches, you find the root cause and fix it without affecting the expected workflow of the product. All of this requires a sturdy feedback loop and collaborative automation tools.
During this process, you might also add new test cases to validate an instance more thoroughly. In such cases, you need to modify the data file and the driver script to fit requirements.
With an efficient test automation architecture, there are many benefits DDT frameworks can bring to your release cycle. This is what we discuss in the next section.
Advantages of Data-Driven Testing
The ability to parametrize your testing is extremely important at scale:
Regression testing: Regression testing revolves around having a set of test cases that are triggered to run at every build. This is to ensure that the additions made to the software for the latest release do not affect the previously working functionality of the software. Data-driven testing (DDT) accelerates this process. Since DDT makes use of multiple sets of data values for testing, regression tests can run for end-to-end workflow for multiple data sets.
Reusability: It creates a clear and logical separation of the test scripts from the test data. In other words, you don't have to modify the test cases over and over again for different sets of test input data. Separating variables (test data) and logic (test scripts) makes them both reusable. Changes in either the test script or the test data will not affect the other. If a tester wants additional test data to be added, he can do so without disturbing a test case. Likewise, if a programmer wants to change the code in the test script, he can do so without worrying about the test data.
Limitations of Data-Driven Testing
DDT enables scale, but there are certain limitations with its methodology.
In a cycle where you are testing data continuously, the 'right data set' is hard to come by! Data validations are time-consuming processes, and the quality of such tests is dependent on the automation skills of the SDETs.
Although DDT separates test scripts and test data, it's important to not kill the job prematurely. Sometimes, to save time, SDETs program the script to only test up to a certain number of rows in a large dataset, which leaves room for errors with other rows of input data.
For a tester, debugging errors, even in a DDT environment, may be difficult due to the lack of exposure they have to a programming language. They would generally not be able to identify logical errors while a script runs and throws an exception.
Increased documentation. Since DDT approaches testing in a modular way, there will be an increased need to have them documented to make it easier for all team members to know the structure and workflow of the framework and automation. Such documentation would be around script management, its infrastructure, results obtained at different levels of testing, and so on.
Best Practices of Data-Driven Testing
To make data-driven testing as efficient as it can get, here is a checklist of best practices you should implement:
Testing with Positive and Negative Data: Everyone tests for positives, but testing the negatives, aka exceptions, is also equally important. A system's performance is gauged by its ability to handle exceptions. These exceptions can occur because of a worst-case scenario that was reproduced in the system at some point. An efficient system should be designed to handle these exceptions well.
Driving dynamic assertions: Driving dynamic assertions that augment the pre-test values/scenarios into the latest ones are essential. Verifications get critical during code revisions and new releases. At this time, it's important to have automated scripts that can augment these dynamic assertions, i.e., include what was previously tested into the current test lines.
Minimizing manual effort: Teams often still rely on manual interventions to trigger an automated workflow. This should be minimized. When we have a workflow with multiple navigational or re-directional paths, it's best to write a test script that can accommodate all of this because a manual trigger is never an efficient way to test a navigational flow. Therefore, it is always a best practice to have the test-flow navigation coded inside the test script itself.
The perspective of the test cases: Perspective should also be considered! This is more of an insightful testing practice than a logical one. If you are interested in checking the workflow, you run basic tests to avoid a break or an exception that is anticipated somewhere in the process. But having the same tests extended for additional capabilities, such as security and performance, will provide fool-proof coverage into the existing network of the design. For instance, you can test the performance of the same workflow by introducing data that meets the max limits of a product – by observing the latency of the load, get-pull from APIs, and so on.
Some hygiene tips for data-driven testing:
Try to form tests that create their own scenario test data.
Ensure tests don't make any permanent changes to the database.
Include tests that cover positive as well as negative test scenarios.
Create automated test scripts that can easily be modified for various data scenarios.
Place test data in one storage format for all test cases, be it an excel spreadsheet or a table.
Refer to the test result report generated for any errors in the test execution due to data issues.
How does Data-Driven Testing Work?
Complimentary to the architecture as explained in the previous section, DDT accommodates both positive and negative test cases in a single flow of the test.
Test data is stored in a columnar distribution, a table, or a structure that mimics a spreadsheet format. This storage canvas is a test table/data file. This file contains all inputs to different test scenarios. It also contains values tagged as ‘expected output’ in a separate column.
Assume that we have the following data table recorded that only has positive test cases recorded.
A script is written to read the data from the data file, such that the test input is picked up from every cell of the data file and substituted as the variable in the run-time flow. This is called a Driver Script. Now that tools automate this process, a Driver Script does not need actual programming. Based on the tool's specifications, all you'll have to do sometimes is connect data sets to the test cases.
Testsigma enables you to create Test Data Profiles outside your scripts and manage large data sets (positive and negative) in plain English and with a codeless, point-and-click module.
The driver script is written in a way where it's enabled to 'read' a file, and pick up a variable from the data file in a predefined format (for instance, read column A, cell 2A; column B, cell 2B; Name C, cell 3C). It also performs a logic or runs this through an application and 'writes' the output in column E. For example, in the above data file, assuming that the script is drafted fairly straightforward, will open the file > read 'Dan' > read 'rown' > read 'Hotel 1' > Run through code at runtime > outputs a value '2' which is fed in column E. If the script has run 3 times, then the table would look like this:
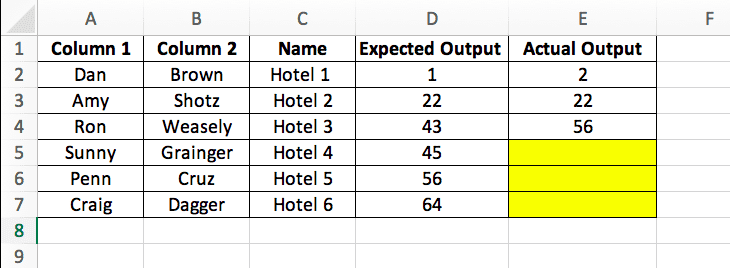
The highlighted cells are blank, as the assumption here is that the computation was incomplete. Once all the tests run, the outputs recorded in Columns D and E are compared. If they match, the design is passed to production. If not, feedback that lists problems with an RCA (Root Cause Analysis) must be shared across teams.
Examples of DDT with its Implementation Structure
Let us see an example of DDT. Consider the Login Page of a Hotel Reservation website. A pseudo workflow could be as follows:
A test data file is created as TestData_HotelReservation.csv (Comma Separated Values)
This file contains inputs given to the driver script and expected results in a table
The driver script for the above data file will be, data = open(‘TestData_HotelReservation.csv’).read() lines = data.splitlines()
Steps performed for above driver scripts are as follows:
Read Value1
Read Value2
Read Operator
Calculate the result using an operator on Value1 and value2
Finally, compare the expected result with the actual result
Data-Driven Testing with Testsigma
Testsigma enables data-driven testing for the below storage types:
Data tables created within Testsigma
Excel files.
.json files.
The excel and .json files can be easily imported into Testsigma. A plain English test script can then be configured to read data from these data files by the toggle of a button. See how it works.
Creating a Data-Driven Automation Framework
A test automation framework is a set of components like test-data handling capabilities, object and className repositories, templates, and more that enables teams to automate tests coherently and uniformly. It makes automated tests easier to maintain and reuse.
An automation framework can be built to enable one or more of the following:
Linear test scripting
The Test Library Architecture Framework
The Data-Driven testing Framework
The Keyword-Driven or Table-Driven Testing Framework
The Hybrid Test Automation Framework
Test Data Generation
Test data can either be the actual data taken from previous operations or a set of artificial data designed for testing purposes. Test data is created depending on the testing environment before the test execution begins.
Test data can be generated in the following ways:
Copy of data from production to testing environment.
Copy of data from client machines.
Manual test data generation process.
Automated test data generation tools, e.g.: SQL data generator, DTM data generator.
Back-end data injection: Back-end Data Injection provides swift data injection in the system. It enables the creation of backdated entries, which is a huge drawback in both manual as well as automated test data generation techniques.
Third party tools: Testsigma has a built-in test data generation feature.
If test data is generated during the test execution phase, it is quite possible that you may exceed your testing deadline. In order to simplify the test management process, sample data should be generated before you begin test execution. Refer here to know more details on test data generation.
Now that we understand what test data is, we very well understand and are in terms of the fact that test data is a critical piece of programming or testing an application. Test Data cannot be random all the time. Therefore, you'll need to scrape data usable data, which can be from past operations collected and archived. Other ways to gather data are:
Through brainstorming and manually collecting data.
Mass copy from the production environment to the staging environment.
Usage of automated test data generation tools.
Using legacy client systems to duplicate or fork data.
How does one validate such test data and, therefore, test cases? This is where BDT comes into play. In other words,Behavior Driven Testing supports management staff with limited technical knowledge.
Behavior-Driven Testing and DDT
Testing need not be a technical function all the time. In complex systems, some applications require logical test data such as dates in terms of duration, discounts and other mathematical calculations, temperature measurements, and so on. This type of data is most often required in real-time systems, such as areas related to logistics and inventory management. The skill set here is inclined more toward logical, rational, and research-based expertise rather than tech skills. These kinds of tasks are often palmed off to management personnel or product owners. Test automation strategy also adapts to this personnel, and that is whereBehavior Driven Testing comes into play.
Behavior Driven Testing is focused on the behavior of users for an application rather than the technical functions of the software. The test cases are written in a natural language that is verbose and easily understood by anyone, encouraging clear cross-functional communication across teams.
Conclusion
When you can run, why crawl? Automation has sped up software testing by leaps and bounds, enabling Agile delivery at all scales and scopes. Data-driven testing is just an extension of that automation. In this guide, we took an in-depth look into the nuances of practical parametrized testing that works.